


Missing Protein In Fragile X Syndrome Is Key To Transporting Signals Within Neurons
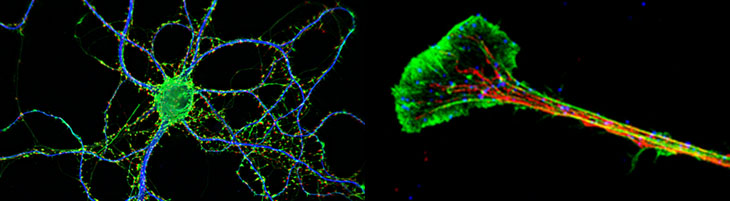
During brain formation billions of neurons must form properconnections or “wiring” to ensure normal function and cognitionthroughout development. This process is very dynamic: individualneurons form many connections initially, but only a fraction of thesepersist into adulthood. The retention of important connections, or synapses, for brain function appears toinvolve fine tuned expression of genes at precise moments in development. Recent advances in understandingthe key genetic pathways that contribute to normal brain development now provide an opportunity to identifyboth the genetic and environmental contributions to ASDs. Based on these data we hypothesize that ASDsresult from a disruption of temporally fine-tuned genetic programs that regulate the formation and maturationof synapses, the place where individual neurons transmit signals that are the basis of learning, memory andbehavior. To test our hypothesis in the context of this dynamic synaptic process, we have quantified changesin the number and type of synapses during the early synapse formation and refinement period just afterbirth in one of the best known mammalian genetic models of autism, the fragile X syndrome mouse. We havefocused our studies on synaptic scaffold proteins and neural cell adhesion molecules (NCAMs) that initiatesynapse formation and are now implicated as “hotspots” for genetic mutation in autism pathogenesisin humans. Live cell imaging of synapse dynamicsusing these markers will be highlighted to show howactivity-dependent changes result in a shift in thebalance of molecules that directly regulate excitatoryand inhibitory circuitry in this single-gene model ofautism. (Supported by NIH grant GM084805 to J.D.)